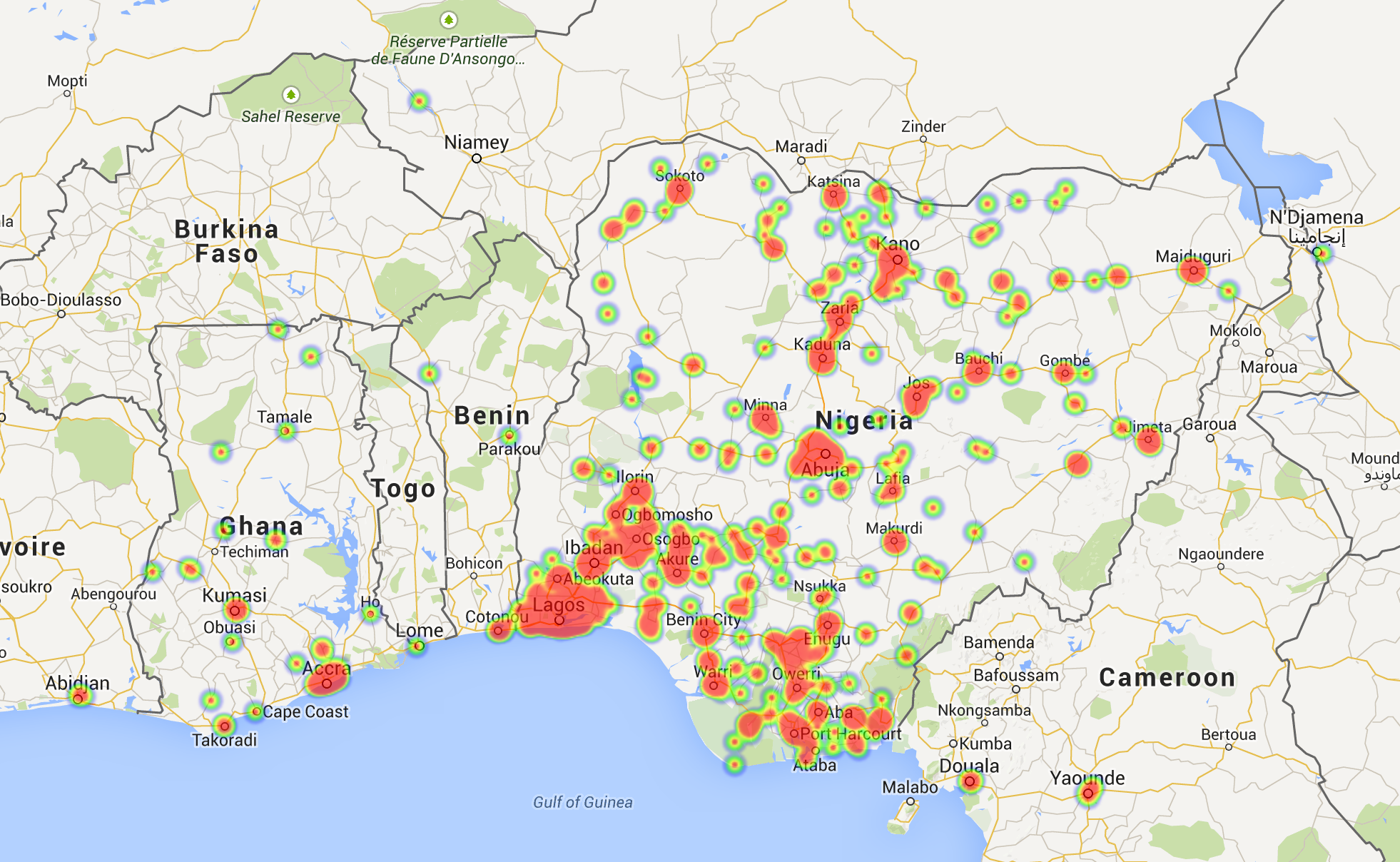
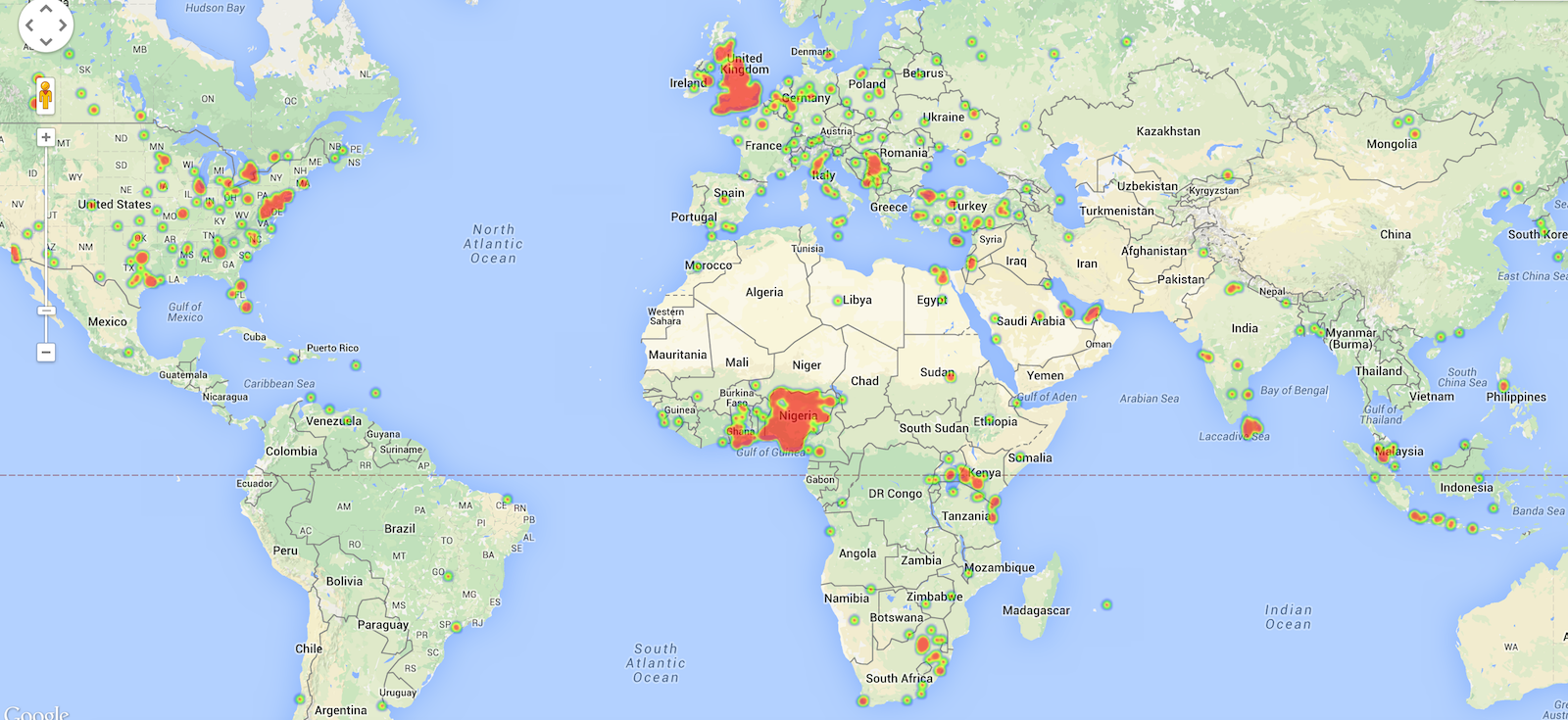
[This is a short summary of material that I prepared for final year project students]
I assume that you already have a vague idea of what a bitcoin is and you have a simple understanding of the mechanisms behind transactions: payments are made to addresses (that are anonymous, in the sense that they cannot be directly linked to a specific individual), and all transactions are public. Transactions are collected in blocks, and blocks are chained together in the blockchain.
You can think of the blockchain as a big database that is continuously updated and is accessible to everyone. You can download the full blockchain using a software like Bitcoin Core. After installing the software, it will take a couple of weeks for your installation to synchronise. Notice that, at the time of writing, the blockchain has a size of over 130 Gb, take this into consideration…
If you have blockchain data available (not necessarily the whole blockchain, you can also work on subsets of it), it can be analysed using Java. You could do all the work from scratch and read raw data from the files etc. Let’s skip this step and use a library instead. There are several options available in most programming languages. I’m going to use Java and the bitcoinj library. This is a big library that can be used to build applications like wallets, on-line payments, etc. I am going to use just its parsing features for this post.
First of all download the jar file for the library at https://bitcoinj.github.io/ (I’m using https://search.maven.org/remotecontent?filepath=org/bitcoinj/bitcoinj-core/0.14.4/bitcoinj-core-0.14.4-bundled.jar). Then, download SLF4J (https://www.slf4j.org/download.html), extract it, and get the file called slf4j-simple-x.y.z.jar (in my case: slf4j-simple-1.7.25.jar). Add these two jar files to your classpath and you are ready to go.
Let’s start from a simple example: compute (and then plot) the number of transactions per day. This is the code, heavily commented, just go through it.
import java.io.File; import java.text.SimpleDateFormat; import java.util.LinkedList; import java.util.List; import java.util.HashMap; import java.util.Locale; import java.util.Map; import org.bitcoinj.core.Block; import org.bitcoinj.core.Context; import org.bitcoinj.core.NetworkParameters; import org.bitcoinj.core.Transaction; import org.bitcoinj.params.MainNetParams; import org.bitcoinj.utils.BlockFileLoader; public class SimpleDailyTxCount { // Location of block files. This is where your blocks are located. // Check the documentation of Bitcoin Core if you are using // it, or use any other directory with blk*dat files. static String PREFIX = "/path/to/your/bitcoin/blocks/"; // A simple method with everything in it public void doSomething() { // Just some initial setup NetworkParameters np = new MainNetParams(); Context.getOrCreate(MainNetParams.get()); // We create a BlockFileLoader object by passing a list of files. // The list of files is built with the method buildList(), see // below for its definition. BlockFileLoader loader = new BlockFileLoader(np,buildList()); // We are going to store the results in a map of the form // day -> n. of transactions Map<String, Integer> dailyTotTxs = new HashMap<>(); // A simple counter to have an idea of the progress int blockCounter = 0; // bitcoinj does all the magic: from the list of files in the loader // it builds a list of blocks. We iterate over it using the following // for loop for (Block block : loader) { blockCounter++; // This gives you an idea of the progress System.out.println("Analysing block "+blockCounter); // Extract the day from the block: we are only interested // in the day, not in the time. Block.getTime() returns // a Date, which is here converted to a string. String day = new SimpleDateFormat("yyyy-MM-dd").format(block.getTime()); // Now we start populating the map day -> number of transactions. // Is this the first time we see the date? If yes, create an entry if (!dailyTotTxs.containsKey(day)) { dailyTotTxs.put(day, 0); } // The following is highly inefficient: we could simply do // block.getTransactions().size(), but is shows you // how to iterate over transactions in a block // So, we simply iterate over all transactions in the // block and for each of them we add 1 to the corresponding // entry in the map for ( Transaction tx: block.getTransactions() ) { dailyTotTxs.put(day,dailyTotTxs.get(day)+1); } } // End of iteration over blocks // Finally, let's print the results for ( String d: dailyTotTxs.keySet()) { System.out.println(d+","+dailyTotTxs.get(d)); } } // end of doSomething() method. // The method returns a list of files in a directory according to a certain // pattern (block files have name blkNNNNN.dat) private List<File> buildList() { List<File> list = new LinkedList<File>(); for (int i = 0; true; i++) { File file = new File(PREFIX + String.format(Locale.US, "blk%05d.dat", i)); if (!file.exists()) break; list.add(file); } return list; } // Main method: simply invoke everything public static void main(String[] args) { SimpleDailyTxCount tb = new SimpleDailyTxCount(); tb.doSomething(); } } |
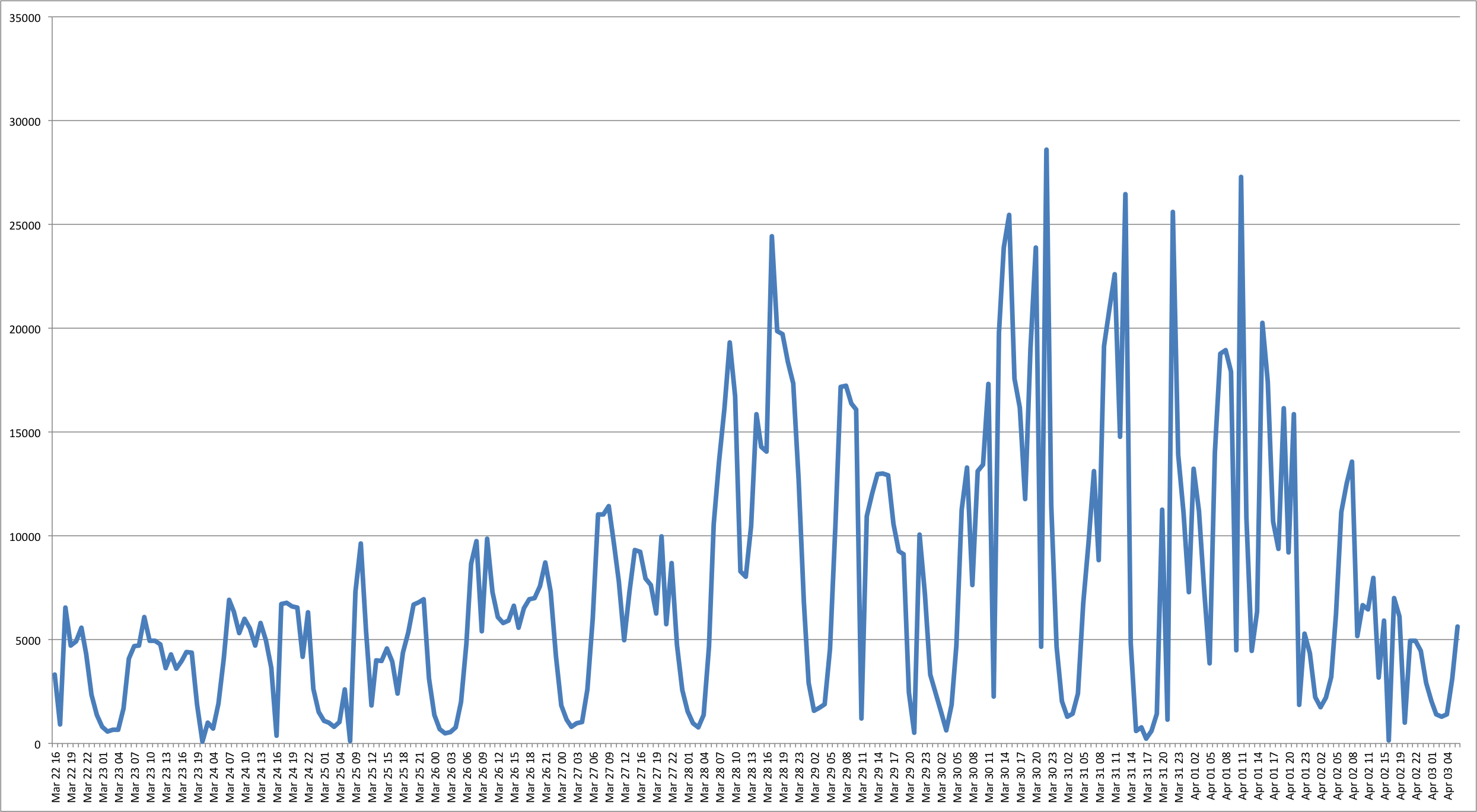
This code will print on screen a list of values of the form “date, number of transactions”. Just redirect the output to a file and plot it. You should get something like this (notice the nearly exponential growth in the number of daily transactions):
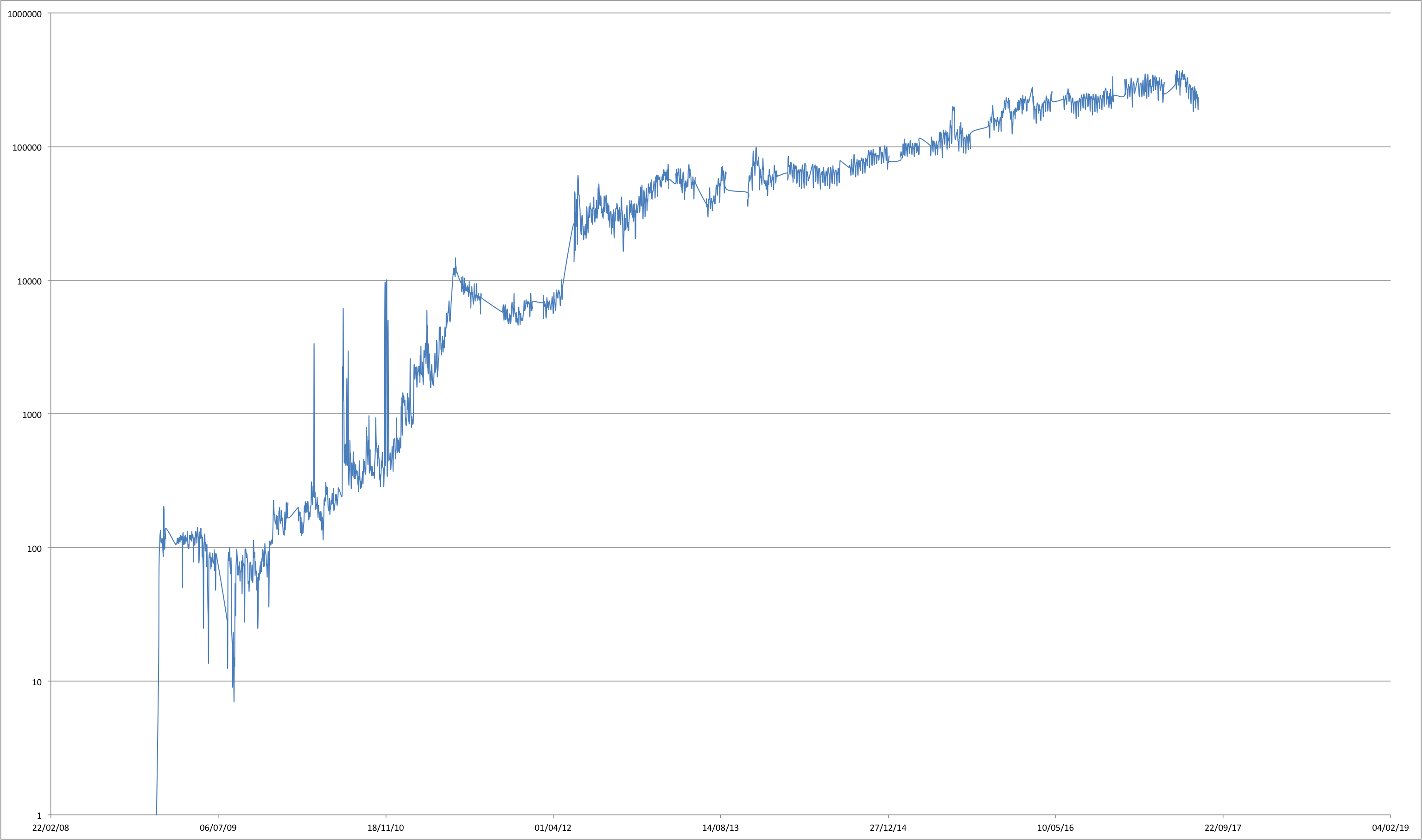
Number of transactions per day (log scale)
I am very impressed by the performance of the library: scanning the whole blockchain with the code above took approximately 35 minutes on my laptop (2014 MacBook Pro), with the blockchain stored on an external HD connected using a USB2 port. It took approximately 100% of one processor and 1 Gb of RAM at most.
A slightly more complicated example took 55 minutes: computing the daily distribution of transaction size. This requires adding a further loop in the code above to explore all the transaction outputs (and a few counters along the way). The buckets are 0-10 USD, 10-50 USD, 50-200 USD, 200-500 USD, 500-2000 USD, 2000+ USD (BTC/USD exchange rate computed by taking the average of opening and close value for the day).
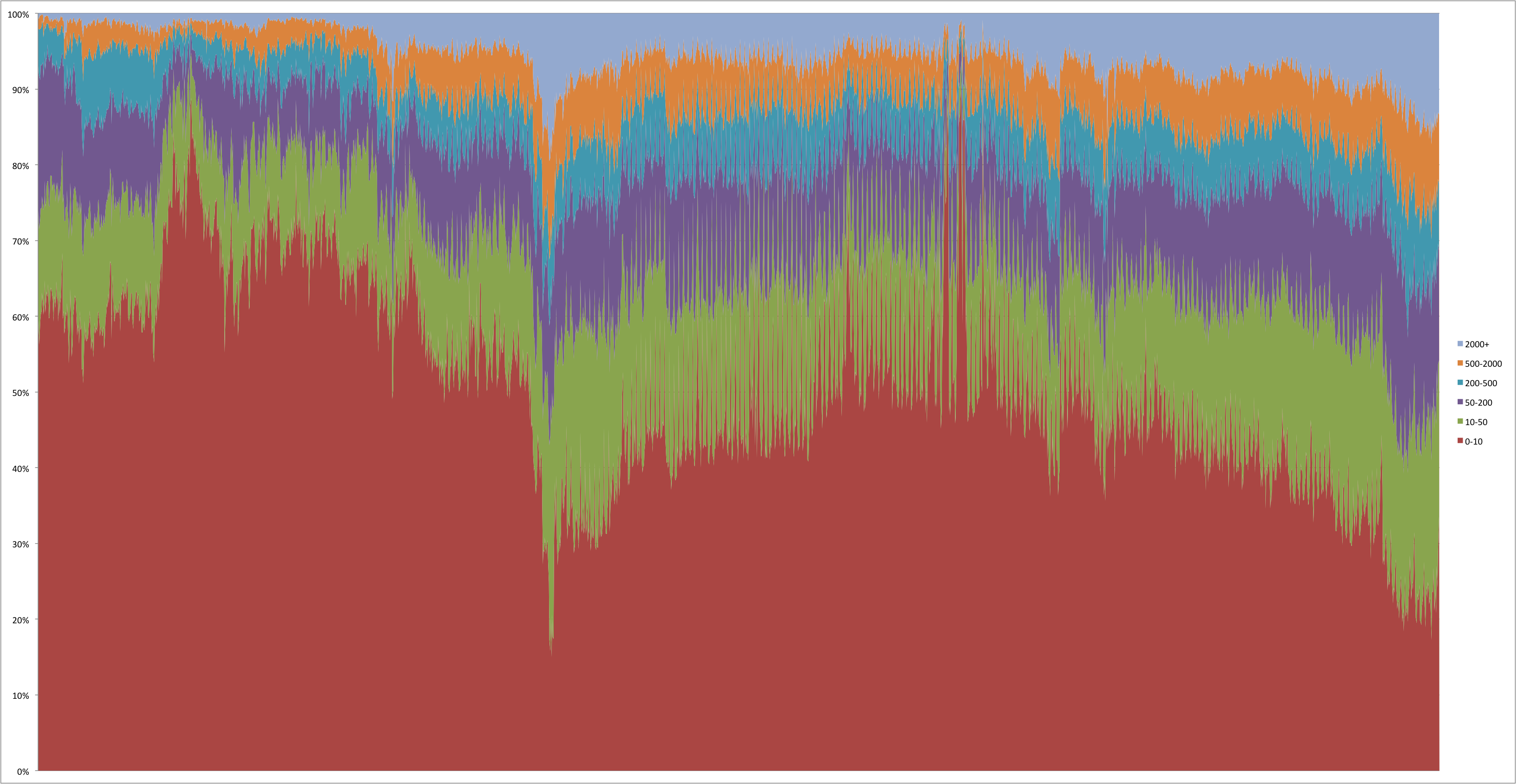
Tx size distribution (in USD), October 2011 – July 2017
 . What about one right and 29 wrong? This is
. What about one right and 29 wrong? This is  multiplied by
multiplied by  , but you should also remember that there are 30 different ways to get a question right (it could be the first or the second or … or the thirtieth). So, overall, the probability of getting 1 question right and 29 wrong is
, but you should also remember that there are 30 different ways to get a question right (it could be the first or the second or … or the thirtieth). So, overall, the probability of getting 1 question right and 29 wrong is  . This is nearly ten times more likely than getting all the questions wrong.
. This is nearly ten times more likely than getting all the questions wrong. questions right and 30-
questions right and 30- , but we should also multiply this number by the possible combinations of n elements out of 30, that is:
, but we should also multiply this number by the possible combinations of n elements out of 30, that is:![\[ P(n) = (\frac{1}{4})^n \cdot (\frac{3}{4}))^{(30-n)} \cdot \binom{30}{n} \]](https://www.rmnd.net/wp-content/ql-cache/quicklatex.com-a9e6d20a10b875e08be5349d1cbe53e1_l3.png "Rendered by QuickLaTeX.com")
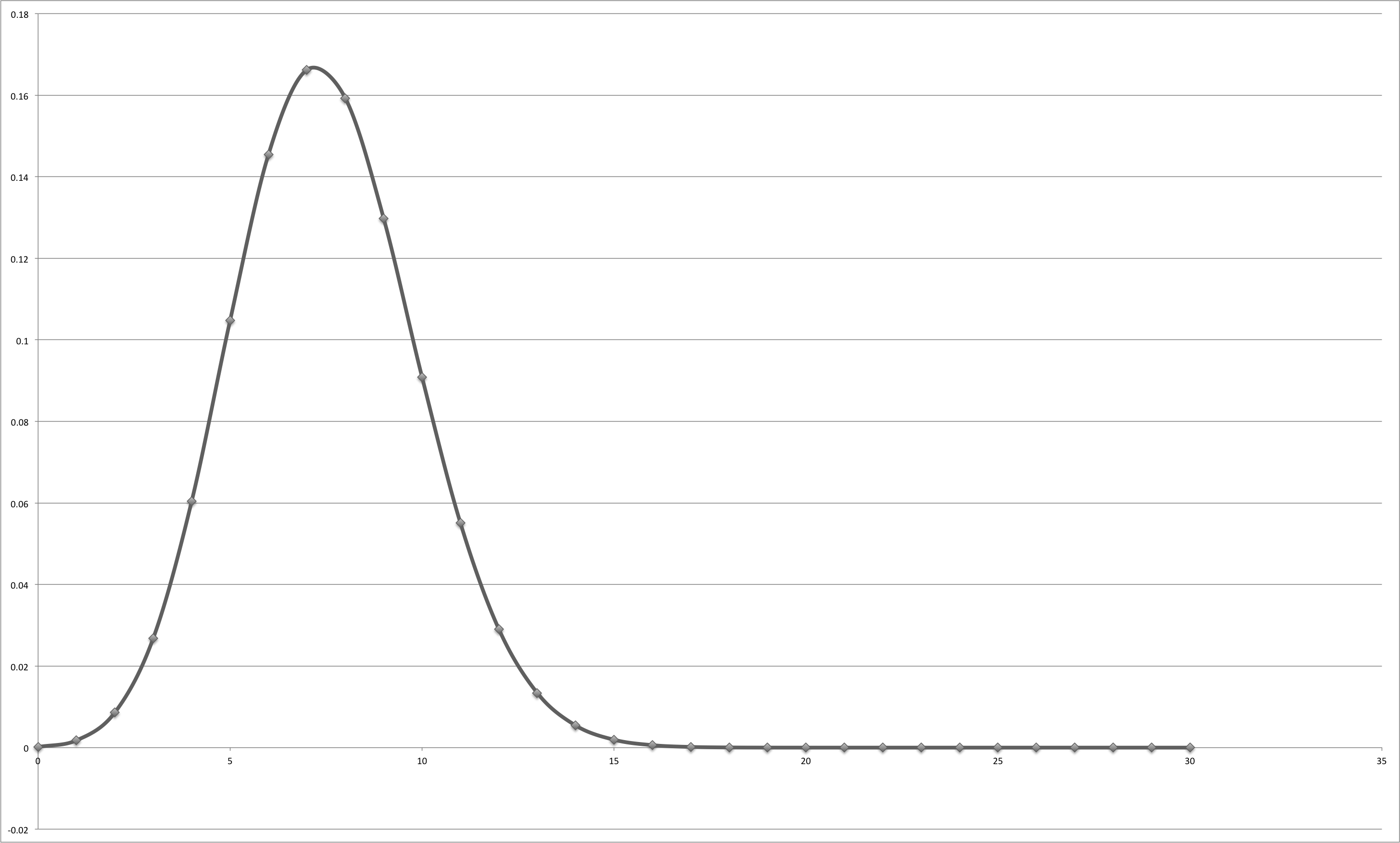
 . So, on average, a “random answerer” would get 7.5 questions right. What is the probability of passing the test by answering randomly? We need a cumulative function for this. Let’s plot the probability of passing a test where it is required to answer
. So, on average, a “random answerer” would get 7.5 questions right. What is the probability of passing the test by answering randomly? We need a cumulative function for this. Let’s plot the probability of passing a test where it is required to answer  as defined above):
as defined above):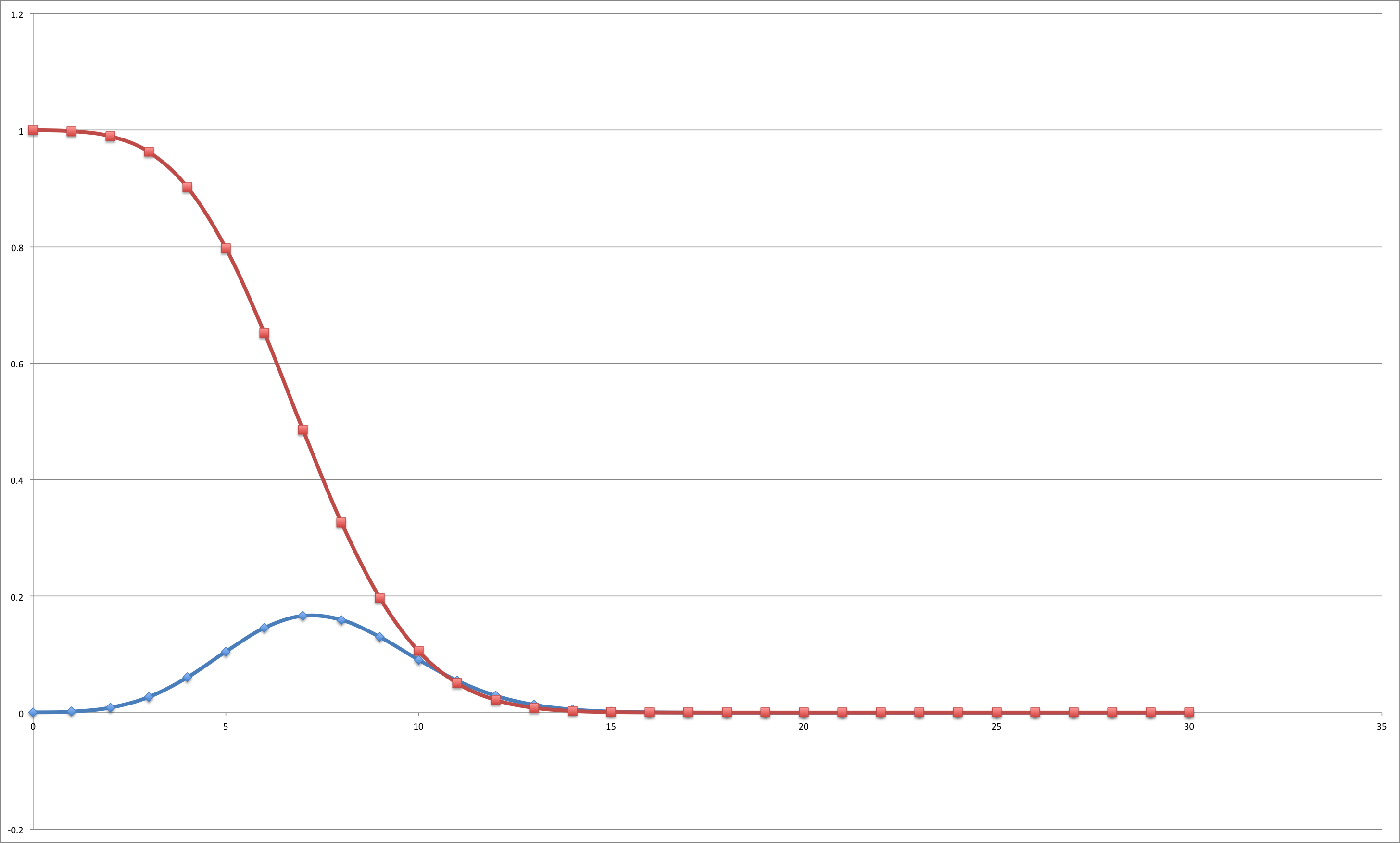
 . Going back to the original question: the probability that a student answering randomly passes the test is 0.1%.
. Going back to the original question: the probability that a student answering randomly passes the test is 0.1%.