Communication between a PC and a TinyOS mote is normally achieved using Java. But what if you want to use Racket?
Communication between a PC and a TinyOS mote is normally achieved using Java. But what if you want to use Racket?
Here I give a very simple overview of how packets from a TinyOS mote connected via USB to a Linux or Mac machine can be read using Racket (I have not tried Win). An advantage of this approach is that it does not require the installation of TinyOS, which could be quite cumbersome… However, it may be a good idea to have a working installation of TinyOS on your machine so that you can modify the code on the motes. It would be beneficial to have at least a bit of familiarity with nesC (no need to be able to write code, just to understand a little bit what is going on).
As an example, I start from a simple application that broadcasts temperature and humidity. The application can be installed on various motes (just 2 in my configuration) and then a base station collects all the readings. In my case the base station is connected to the PC using a USB port. In my configuration I have a Ubuntu virtual machine running on a Mac where I have configured the TinyOS environment and Racket is running in this virtual machine. The same code runs directly on Mac. We are only interested in the structure of the message being broadcasted. This is a small variation of the standard examples that can normally be found in a .h header file; in my example the header file contains the following:
1 2 3 4 5 | typedef nx_struct BlinkToRadioMsg { nx_uint16_t nodeid; nx_uint16_t humidity; nx_uint16_t temperature; } BlinkToRadioMsg; |
This says that each message contains 2 bytes (16 bits) for nodeid, 2 bytes for humidity and 2 bytes for the temperature, for a total of 6 bytes. Messages are transmitted in TinyOS packets over the wire, and these packets have a special format. See Section 3.6 of the document available at http://www.tinyos.net/tinyos-2.x/doc/html/tep113.html if you want more information. In summary, a packet looks like this:
7e 45 00 ff ff 00 01 06 22 06 00 01 04 5c 18 69 37 6b 7e
where the sequence 7e is a reserved sequence to denote the start and the end of a packet. The actual payload (i.e., the 6 bytes we want to receive) in our case is the sequence “00 01 04 5c 18 69″, where “00 01″ is nodeid, “04 5c” are the two bytes for humidity and “18 69″ are the two bytes for temperature. The rest of the packet includes a CRC check, protocol ID, etc. See link above if you are interested in the details.
To read these packets I modify a little bit the code that is used in firmata.rkt to communicate with an Arduino board using firmata. The idea is simple: I create an input file attached to the USB port and I keep reading bytes. When I recognise a packet, I parse it an print the values of ID, humidity and temperature on screen. Let’s start by creating the input file:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | ;; This is the input file to be defined below (define in null) ;; This is used to open the connection and to launch the reading loop ;; You typically launch it with (open-port "/dev/ttyUSB0)" ;; (check the port name with the command-line instruction motelist) (define (open-port port-name) (printf "Racket-TinyOS starting... please wait\n") ;; This is used to associate the port to the file (set! in (open-input-file port-name #:mode 'binary)) (if (system (string-append "stty -F " port-name " 115200 cs8 cread clocal")) (begin (read-loop) ;; see below for the definition of this ) (error "Could not connect to " port-name) ) ) |
The (read-loop) simply reads one byte at a time and calls itself:
1 2 3 4 | (define (read-loop) (process-input (read-byte in)) (read-loop) ) |
The function (process-input) is where the packet is built:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | ;; This is where we store the packet (define packet null) ;; These are used to define the end-of-packet and start-of-packet sequences (define sop #x7e) ;; start of packet (define eop #x7e) ;; end of packet ;; These are used to record the fact that an end-of-packet ;; (or start-of-packet) have been received (define eop-rec 0) ;; end-of-packet received (define sop-rec 0) ;; start-of-packet received (define (process-input data) ;; First of all we add the byte to the packet (set! packet (cons data packet)) (cond ( (and (= eop-rec 0) (= data eop)) ;; If it is an end-of-packet sequence, we record it (set! eop-rec 1) ) ( (and (= eop-rec 1) (= data sop)) ;; If we find a start of packet after an end-of-packet we parse ;; the packet (we have to reverse it, because it was built in ;; the opposite order) (parse-packet (reverse packet)) ;; and then we start again and we empty the packet. (set! eop-rec 0) (set! packet null) ) ) ) |
Up to this point the code is re-usable for any packet content. In the function (parse-packet), instead, we have to process the bytes according to the message format defined in the header file (see above). This function is defined as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | (define (parse-packet packet) ;; Very easy: ID is at position 10 and 11 ;; Humidity position 12 and 13 ;; Temperature position 14 and 15 ;; These functions get the two bytes into the actual ID, ;; humidity and temperature. ;; for the actual formula (define id (+ (* (list-ref packet 10) 256) (list-ref packet 11))) (define rh (+ (* (list-ref packet 12) 256) (list-ref packet 13))) (define temp (+ (* (list-ref packet 14) 256) (list-ref packet 15))) ;; We then convert RH and temp according to datasheet for sensirion sht11 (set! rh (+ (* rh 0.0367) -2.0468 (- (* 0.00000159 rh rh)))) (set! temp (+ (* temp 0.01) -39.7)) ;; Omissis: print the actual date. See link below for full code. (printf "~a ~a ~a\n" id rh temp) (flush-output) ) |
The final result of this code is the following output
2013/10/29 17:04:55 1 61.36022401 10.379999999999995 2013/10/29 17:05:02 2 35.30190249 23.799999999999997
Where the first number after the time is the node id, followed by the relative humidity, followed by the temperature. I have redirected this output to a file called office-all.txt for one hour, placing one sensor inside my office (with sensor id 2) and one sensor outside the office (sensor id 1). At the end of the hour I split this file with the command-line instruction
grep " 1 " office-all.txt > office-out.txt grep " 2 " office-all.txt > office-out.txt
Then, I plot the temperature with the following gnuplot script:
set timefmt "%Y/%m/%d %H:%M:%S" set xdata time set terminal png font "/Library/Fonts/Arial.ttf" 28 size 1600,1200 set output 'office-temp.png' plot "office-out.txt" using 1:5 title "Outdoor", "office-in.txt" using 1:5 title "Indoor"
This is the final result:
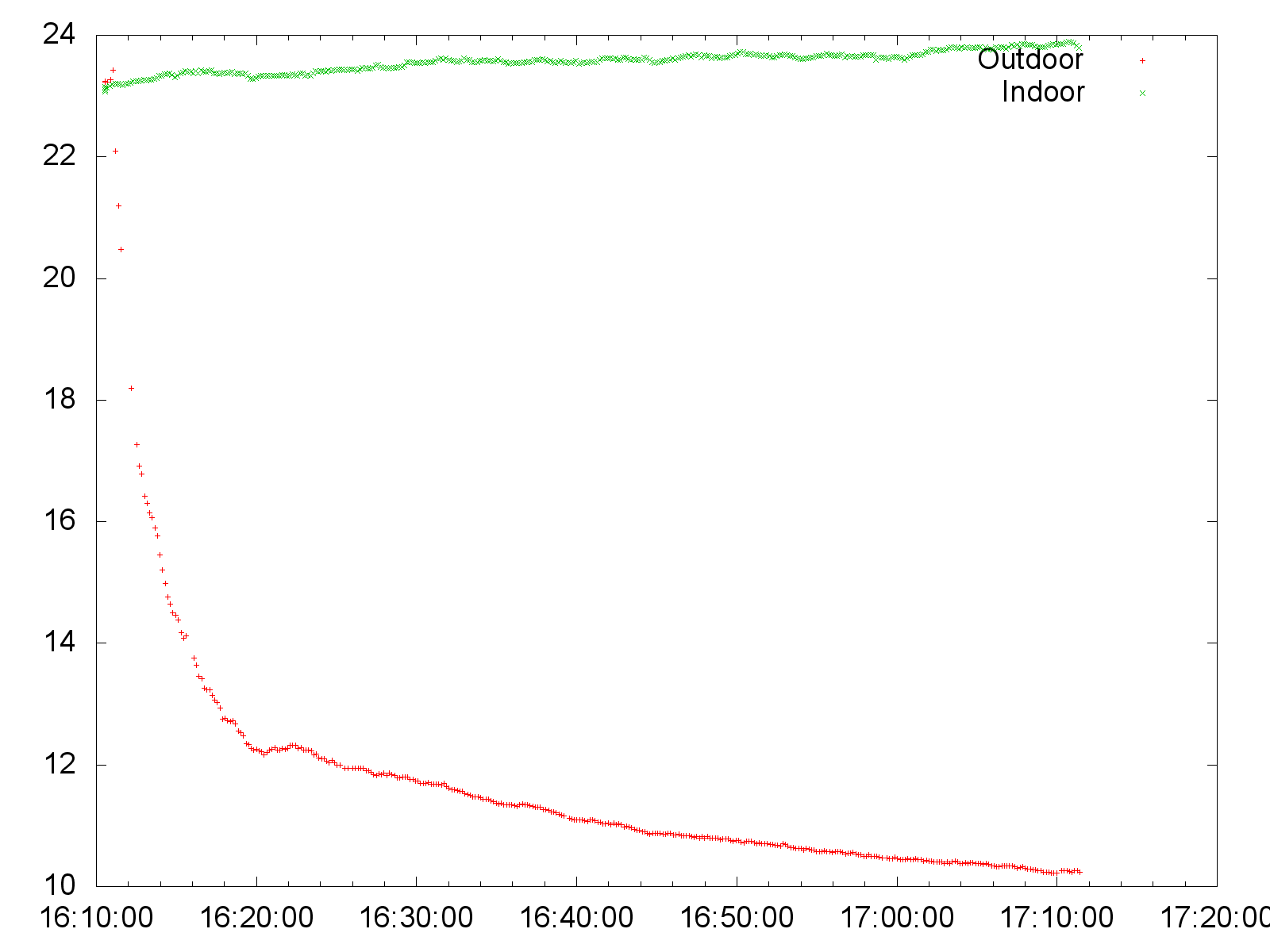 Notice how the indoor temperature remains constant (in green), while the outdoor temperature drops in 10 minutes when the sensor adjusts to the outdoor temperature, and it keeps decreasing as the sun sets. A very similar script for relative humidity produces this graph:
Notice how the indoor temperature remains constant (in green), while the outdoor temperature drops in 10 minutes when the sensor adjusts to the outdoor temperature, and it keeps decreasing as the sun sets. A very similar script for relative humidity produces this graph:
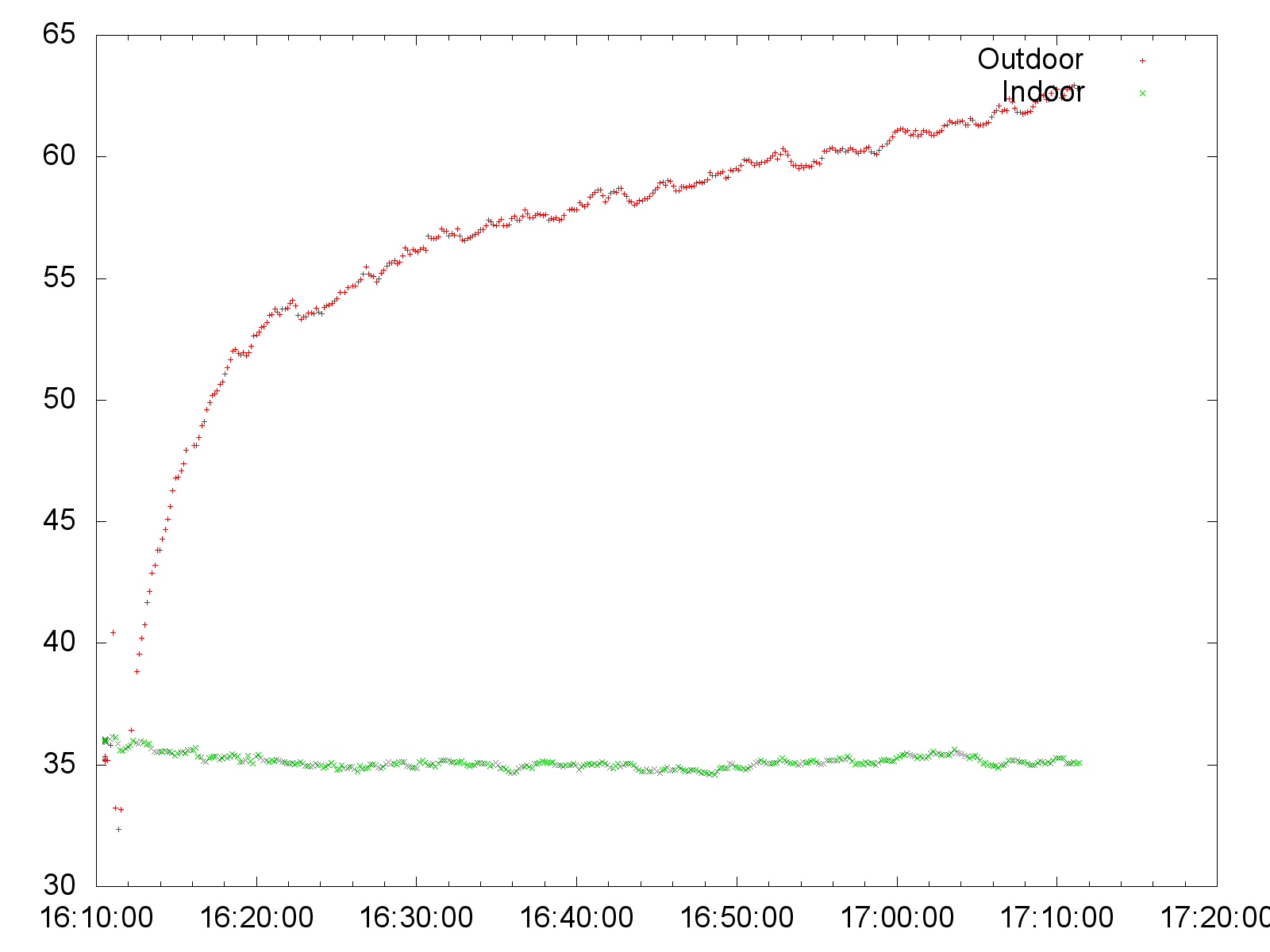
(notice how the relative humidity outside increases as the temperature decreases).
You can download the full Racket code by clicking here.
*** NOTICE!!! *** The parse-packet function is broken: it should take into account the escape sequences before parsing! I leave this to you to fix :-).