A few months ago I prepared a bit of material for the second year course “Software Development” in which I used Java and MongoDB to perform some simple Twitter data analysis. The material introduced MapReduce, JSON and other simple analysis tasks (hourly activity, geo location, most retweeted tweet, etc.). Recently, we installed a new virtual machine with PostgreSQL and Python. In parallel, some colleagues asked me to collect tweets about:
- The India’s Daughter documentary
- Elections in Nigeria.
The first dataset is approximately 1 GB of JSON data (250K tweets), while the second is approximately 11 GB of JSON data (2 million tweets). Is this something that can analysed using a standard SQL-based approach, on a default installation of PostgreSQL? How long will it take? The hardware is a virtual machine with 16 GB of RAM, 2 processors @2.2MHz, 120 GB of disk space. The operating system is Ubuntu 14.04, with PostgreSQL 9.3.6 and Python 2.7.
The starting point is a set of (gzipped) JSON files, each one containing 20,000 tweets. Instead of defining a PostgreSQL table with all the possible fields, I decided to follow the approach described here https://bibhas.in/blog/postgresql-swag-json-data-type-and-working-with-twitter-data/ creating exactly the same table with just two columns: the tweet ID (primay key), and the whole JSON tweet:
CREATE TABLE tweet
( tid CHARACTER VARYING NOT NULL, DATA json,
CONSTRAINT tid_pkey PRIMARY KEY (tid) ) |
If you knew in advance the kind of analysis required it would be more efficient to import only those JSON entries that are required, say the field “created_at” if you were only interested in analysing traffic rates. After creating this table in PostgreSQL, let’s import the tweets. I do this using a simple Python script:
import json
import psycopg2
conn = psycopg2.connect("YOUR-CONNECTION-STRING")
cur = conn.cursor()
with open("YOURJSONFILE") as f:
for tweetline in f:
try:
tweet = json.loads(tweetline)
except ValueError, e:
pass
else:
cur.execute("INSERT INTO tweet (tid, data) VALUES (%s, %s)", (tweet['id'], json.dumps(tweet), ))
conn.commit()
cur.close()
conn.close() |
Exercise: handle the possible exceptions when executing the insert (non-unique key, for instance). Extend the script to read the file name from the command line and wrap everything in a bash script to iterate over the compressed JSON files.
I didn’t time this script, but it took a couple of minutes on the small dataset and probably around 10 minutes on the larger dataset. This could be improved by using a COPY instead of doing an INSERT, but I found this acceptable as it has to be done only once. Now that we have the data, let’s try to stress a bit the machine. Let’s start with extracting the hourly activity in what is probably the most inefficient way one could think of: group by a substring of a JSON object converted to string, as follows:
SELECT SUBSTRING(data->> 'created_at'::text FROM 1 FOR 13),
COUNT(*)
FROM tweet GROUP BY
SUBSTRING(data->> 'created_at'::text FROM 1 FOR 13); |
This extracts the “created_at” field from the JSON object, converts it to a string, and then it takes the substring from position 1 for 13 characters. The full “created_at” field is something like Tue Apr 07 17:21:04 +0000 2015, and the substring is therefore Tue Apr 07 17. Let’s call this on the small dataset (250K tweets) and ask psql to EXPLAIN ANALYZE the query:
explain ANALYZE select substring(data->> 'created_at'::text
[...]
Total runtime: 14602.845 ms
Not bad, just a bit more than 14 seconds! What about the large dataset? How long will it take on 2 million tweets?
explain ANALYZE select substring(data->> 'created_at'::text
[...]
Total runtime: 96553.320 ms
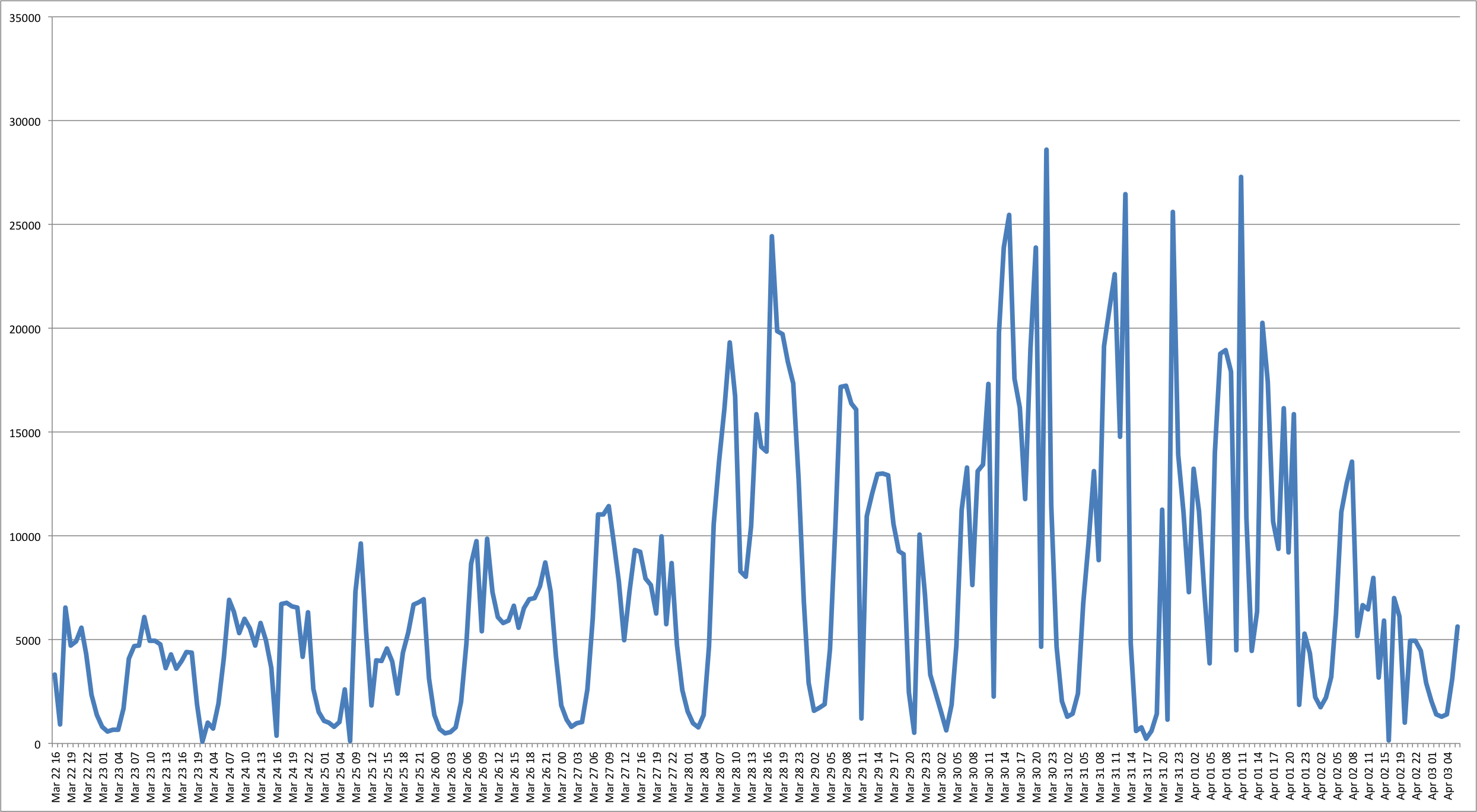
1 minute and a half, again pretty decent if you only run it once. I exported the result as a csv file and plotted, this is the result for the Nigeria elections:
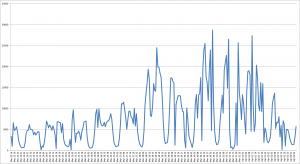
If you need to run multiple queries involving date and times it may be a bit boring to wait nearly 2 minutes each time; can the situation be improved? Yes, as I said above, if you know what you are looking for, then you can optimise for it. Let’s focus on the “created_at” field: instead of digging it out from the JSON object, we could alter the table and add a new column “created_at” of type timestamp and then populate it, as follows:
ALTER TABLE tweet ADD COLUMN created_at TIMESTAMP;
UPDATE tweet SET
created_at = to_timestamp(SUBSTRING(data->> 'created_at'::text FROM 5 FOR 9)||' 2015','
Mon DD HH24 YYYY'); |
The update step will require a bit of time (some minutes, unfortunately I didn’t time it). But now the “group by” query above is executed in 458 ms (less than half a second) on 250K tweets and in 2.365 seconds on 2 million tweets.
Let’s try to extract the location of geo-tagged tweets. First of all, I count all of them on 250K tweets:
explain analyze select count(*) from tweet where data->>'geo' <> '';
[...] Total runtime: 14408.711 ms
For the large dataset the execution time is 147 seconds, a bit long but still acceptable for 2M tweets.
We can then extract the actual coordinates as follows:
SELECT data->'geo'->'coordinates'->0 AS lat,
data->'geo'->'coordinates'->1 AS lon
FROM tweet
WHERE data->>'geo' <> ''; |
You can run this query from the command line and generate a CSV file, as follows:
psql -t -A -F"," -c "select data->'geo'->'coordinates'->0 as lat, \
data->'geo'->'coordinates'->1 as lon from tweet \
where data->>'geo' <> '';"
Exercise: redirect the output to a file, massage it a little bit to incorporate the coordinates in an HTML file using heatmap.js.
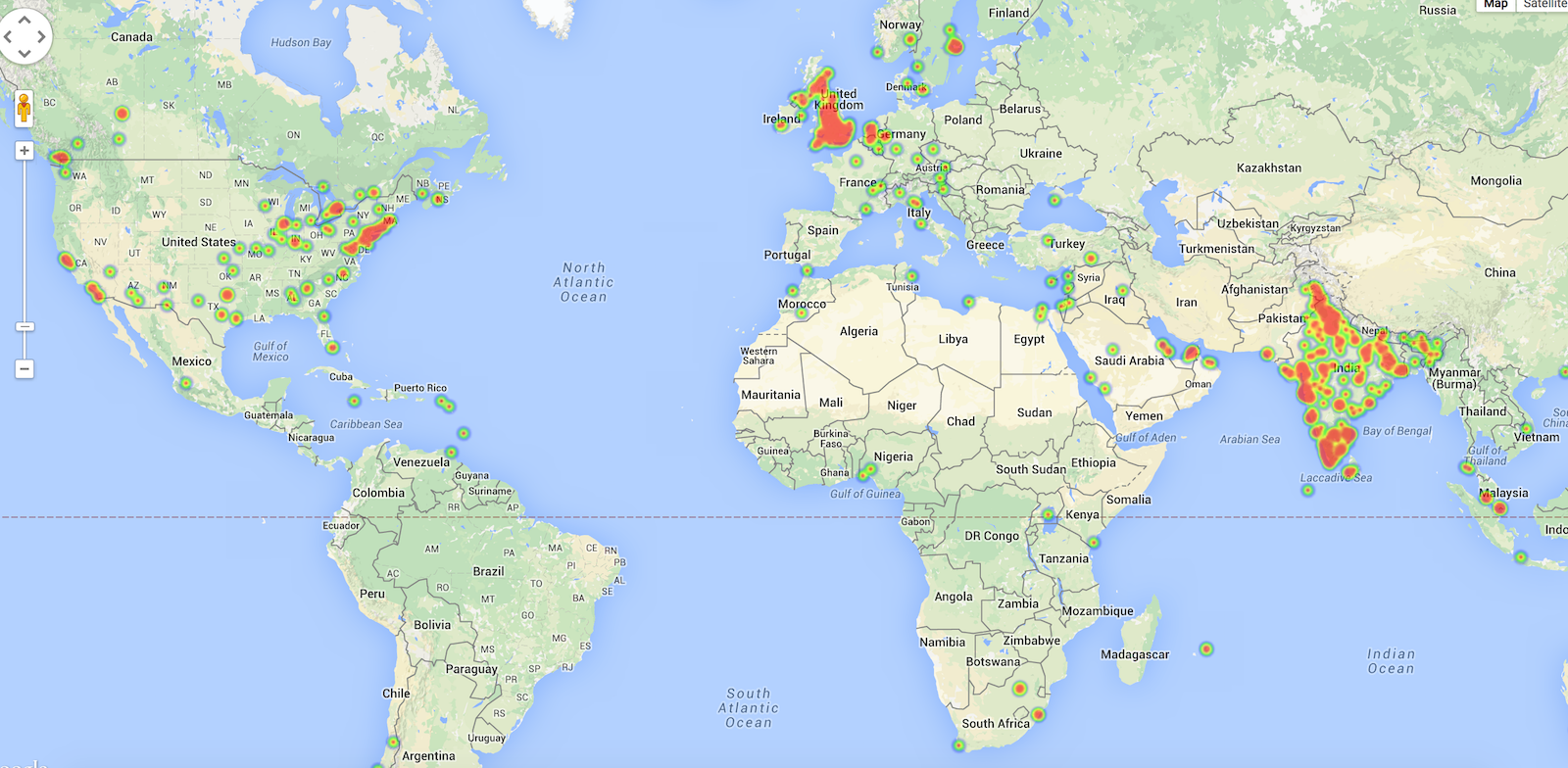
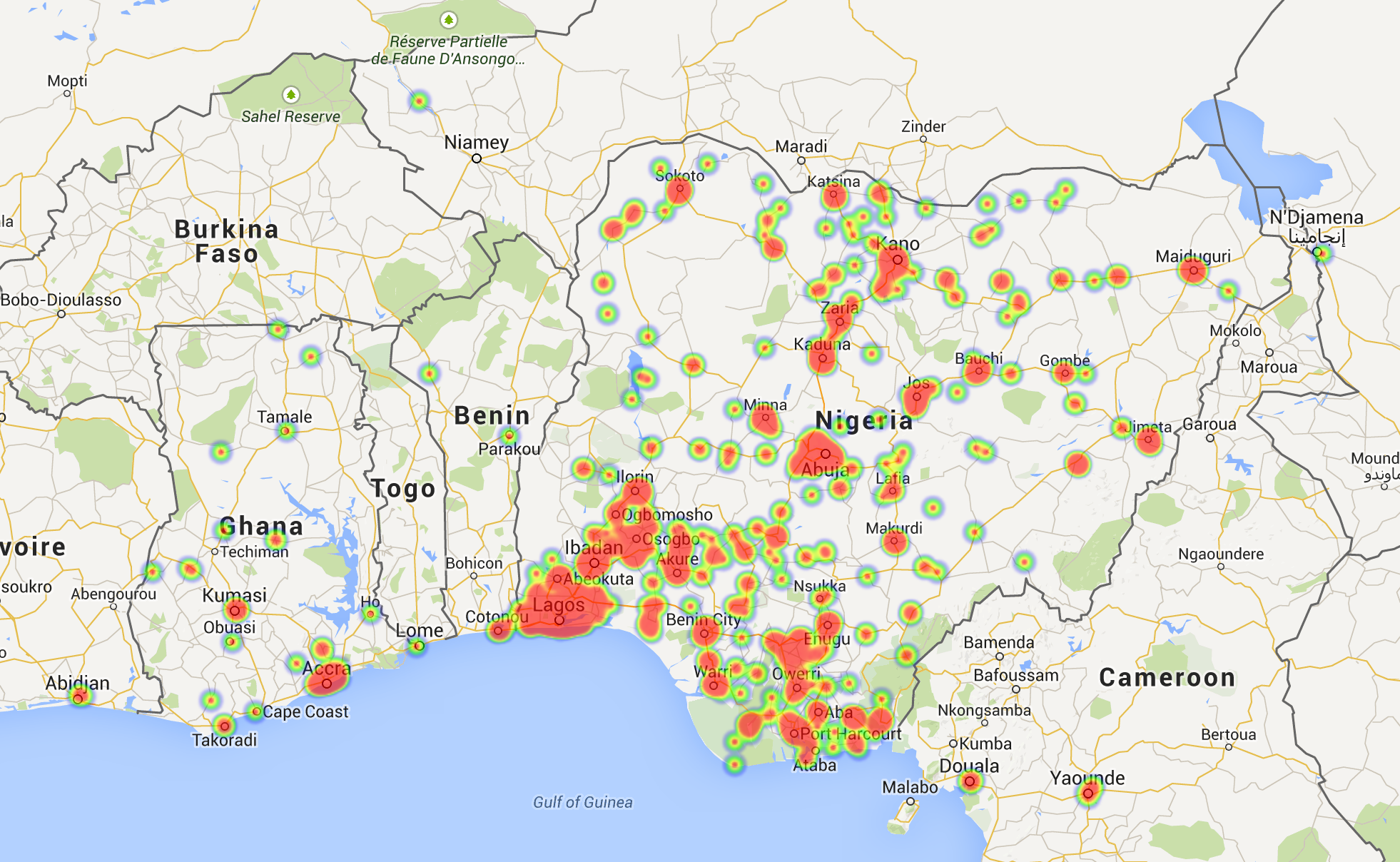
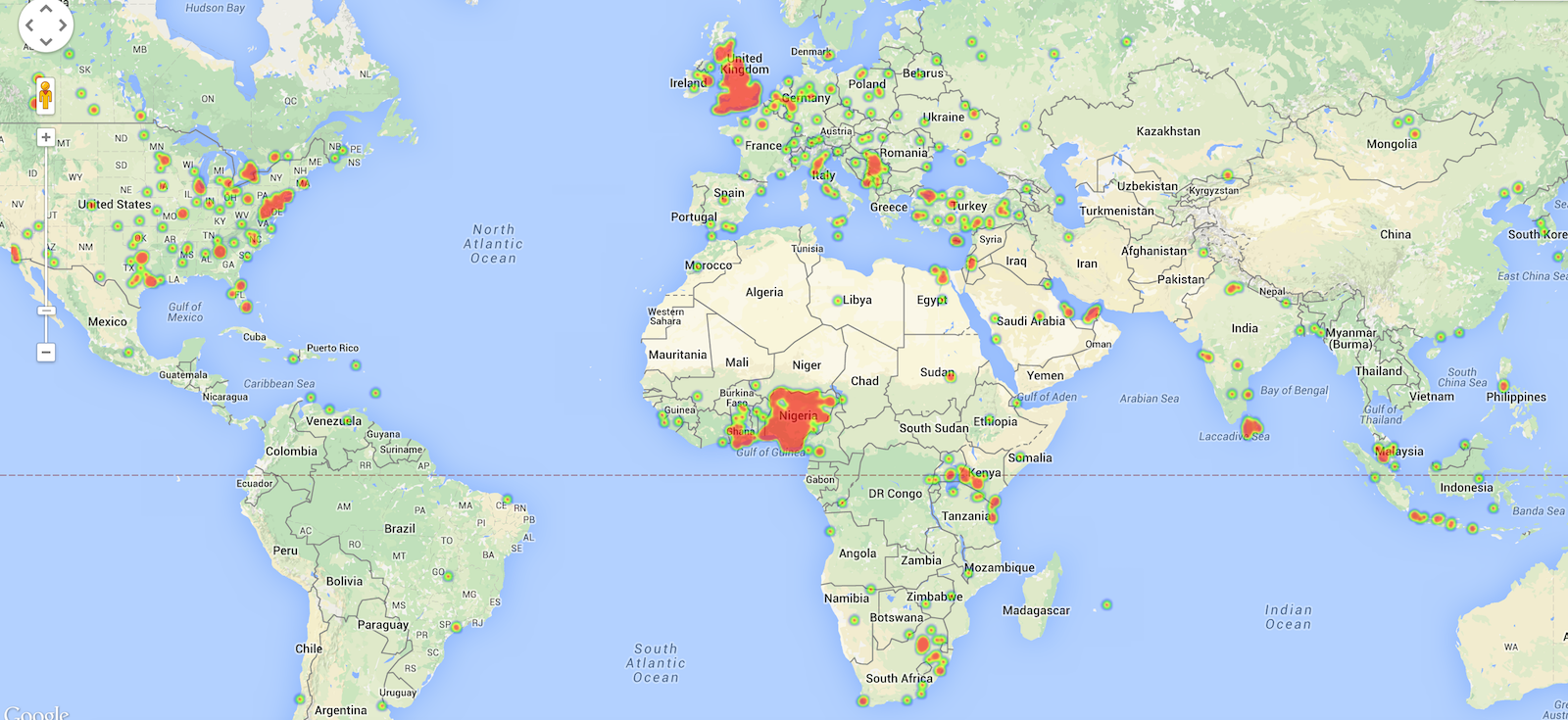
As usual, only approximately 1% of the tweets are geo-tagged. This means more or less 2,500 locations for the India’s Daughter dataset, and approximately 20K locations for the Nigerian elections. These are some plots obtained with these results.
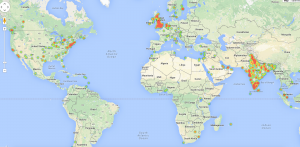
India’s Daughter: heatmap of geo-tagged tweets
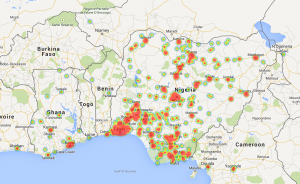
Nigeria elections: heatmap (Nigeria scale)
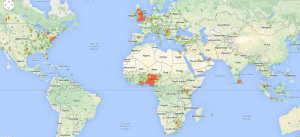
Nigeria elections: heatmap (World view)
PostgreSQL can also be used to do text analysis. Again, we can use the approach described at https://bibhas.in/blog/postgresql-swag-part-2-indexing-json-data-type-and-full-text-search/. You can find more details about the queries used below at this other link: http://shisaa.jp/postset/postgresql-full-text-search-part-1.html. Let’s start by creating an index on the text of each tweet:
CREATE INDEX "idx_text" ON tweet USING gin(to_tsvector('english', data->>'text')); |
The magic keywords here are gin (Generalized Inverted Index, which is a type of PostgreSQL index) and to_tsvector. This last function is a tokenizer for a string, and performs all the stemming using an English dictionary in this case (use the second link above if you want to know the details of all this). The index can be used to find tweets containing specific keywords, in the following way:
SELECT COUNT(tid) FROM tweet WHERE
to_tsvector('english', data->>'text') @@ to_tsquery('Buhari'); |
Notice the special operator @@ used to match a vector of tokens with a specific keyword (you could also use logical operators here!). More interestingly, we can use this approach to compute the most used words in the tweets, a typical MapReduce job:
SELECT * FROM ts_stat('SELECT to_tsvector(''english'',data->>''text'') from tweet')
ORDER BY nentry DESC; |
This is a nested query: first we extract all the tokens, then we use the ts_stat function on all the tokens (see http://www.postgresql.org/docs/9.3/static/textsearch-features.html). The execution time is pretty reasonable: 28 seconds for 250K tweets and 168 seconds for 2M tweets. These are the top 10 words (with number of occurrences) for the India’s Daughter dataset (stemmed, with number of tweets in which they occur):
- indiasdaught, 209773
- india, 55879
- ban, 49851
- documentari, 40541
- rape, 32269
- bbc, 31186
- watch, 25388
- daughter, 19968
- rapist, 20269
- indian, 19417
These are the top 10 words for Nigerian elections dataset:
- buhari, 894709
- gej, 495743
- jonathan, 337640
- presid, 320757
- gmb, 285770
- vote, 273892
- nigeria, 216294
- elect, 221955
- win, 182845
- apc, 161968
How many tweets are retweets? We could take a shortcut and count the number of tweets starting with RT (we could also use the token RT, which is more efficient). Instead, let’s see what happens if we take the long way: we check whether the “id_str” of the “retweeted_status” field is not empty:
SELECT COUNT(*) FROM tweet
WHERE CAST(data->'retweeted_status'->'id_str' AS text) <> ''; |
The query takes a bit less than 20 seconds on 250K tweets and 124 seconds on 2M tweets. More than 162,000 tweets are retweets (64%) for the India’s Daughter dataset, and a bit more than 1,1M in the Nigerian elections dataset (56.5%).
We can also find the most retweeted tweets in each dataset. In the following inefficient query I group tweets by the id of the person being retweeted and I count the number of rows:
SELECT COUNT(*) AS nretweets,
MAX(CAST(data->'retweeted_status'->'user'->'screen_name' AS text))
AS username,
CAST(data->'retweeted_status'->'id_str' AS text) AS retid,
MAX(CAST(data->'retweeted_status'->'text' AS text)) AS text
FROM tweet
GROUP BY retid
HAVING CAST(data->'retweeted_status'->'id_str' AS text) <> ''
ORDER BY nretweets DESC; |
This is the most inefficient query so far: it takes 68 seconds on 250K tweets and 417 seconds (nearly 7 minutes) on 2M tweets.
These are the 2 most retweeted tweets among the 250K tweets on India’s Daughter:
- “Check out @virsanghvi’s take on #IndiasDaughter – https://t.co/BsxTkLK9Yy @adityan”, by mooziek, retweeted 1579 times
- “Forget ban, #IndiasDaughter is must watch. Anyone who watches will understand devastation caused by regressive attitudes. Face it. Fix it.”, by chetan_bhagat, retweeted 1399 times
These are the 2 most retweeted tweets among the 2M tweets on Nigerian elections:
- “‘Buhari’ is the fastest growing brand in Africa. RT if you agree”, by APCNigeria, retweeted 3460 time.
- “Professor Joseph Chikelue Obi : ” The 2015 Nigerian Elections are Over. President Buhari must now quickly move into Aso Rock & Start Work “.”, by DrJosephObi, retweeted 3050 times.
Finally, let’s do a simple sentiment analysis using the vaderSentiment tool. This “is a lexicon and rule-based sentiment analysis tool that is specifically attuned to sentiments expressed in social media”. It is very easy to install using pip and very easy to use, as shown in the following piece of code:
from vaderSentiment.vaderSentiment import sentiment as vaderSentiment
[...]
conn=psycopg2.connect("dbname='indiasdaughter'")
cur = conn.cursor(cursor_factory=psycopg2.extras.DictCursor)
cur.execute("""SELECT (data->'text') as message from tweet""")
[...]
rows = cur.fetchall()
for row in rows:
vs = vaderSentiment(row['message'])
print row['message'],",",vs['compound']
print vs['pos'],",",vs['neu'],",",vs['neg'] |
You can compute the average sentiment by taking the average of vs['compound']. It takes 1 minute and 30 seconds to run this task on 250K tweets, whose average sentiment is -0.17 (slightly negative). It takes 11 minutes and 32 seconds to run the same code on 2M tweets about the Nigerian elections; for this set the average sentiment is (slightly positive).
In conclusion:
- You can use PostgreSQL to perform simple twitter analysis on a dataset of 2 million tweets.
- I have shown some query patterns. These are not optimised, I’m sure performance can be improved in a number of ways.
- Should you use a NoSQL database, Hadoop, MapReduce etc.? Definitely yes, so that you can learn another approach. However, if you are only interested in the results of an off-line analysis, you are already familiar with standard databases and your dataset is of a million of tweets or thereabout, then a standard PostgreSQL installation would work just fine.
- What about MySQL? I don’t know, it would be interesting to compare the results, especially with version 5.6 and full text search.

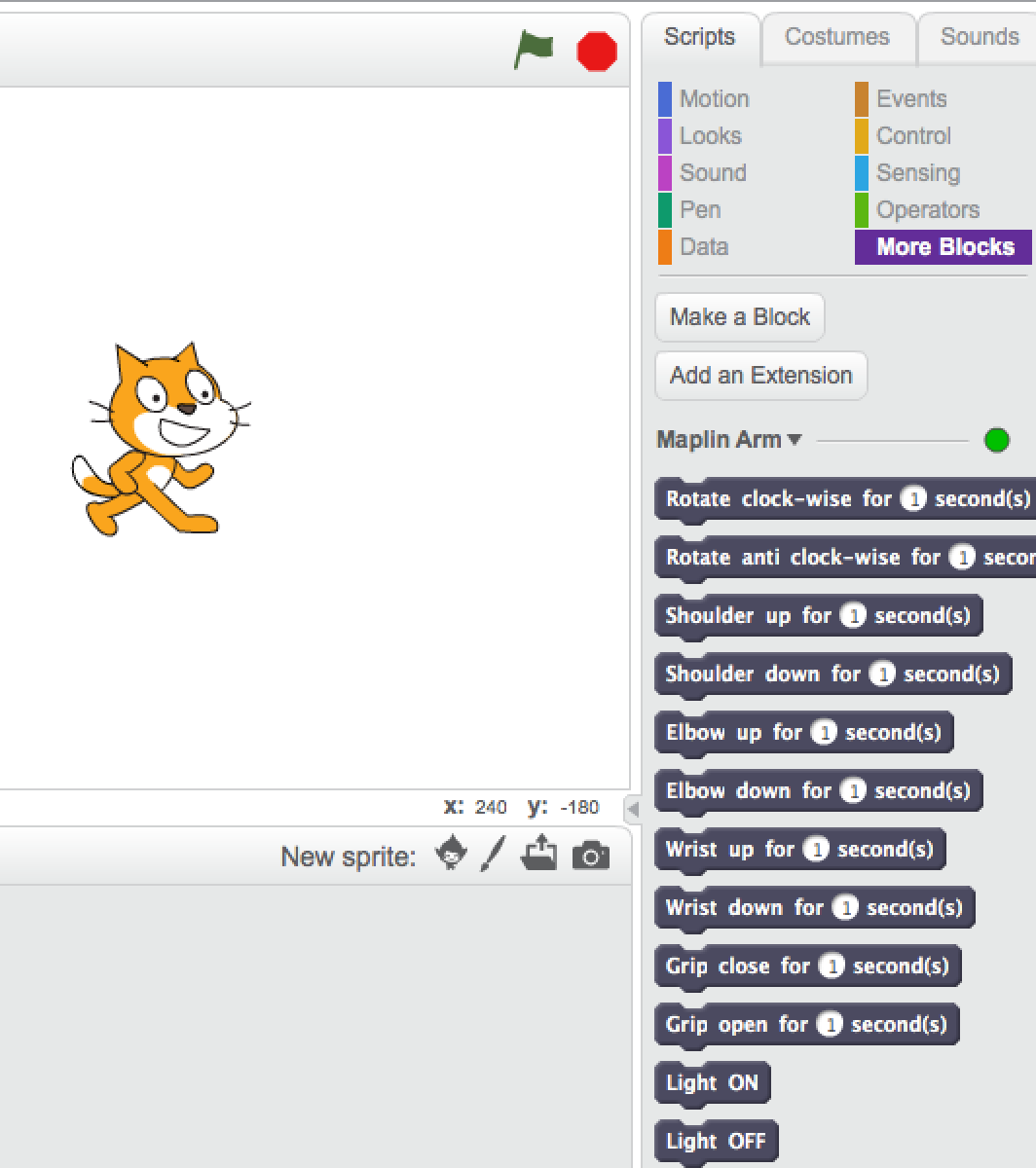 Notice that the dot next to “Maplin Arm” needs to be green: this means that Scratch can talk to the extension. As usual, the proof is in the pudding: https://www.youtube.com/watch?v=tbl3G_gvfjE
Notice that the dot next to “Maplin Arm” needs to be green: this means that Scratch can talk to the extension. As usual, the proof is in the pudding: https://www.youtube.com/watch?v=tbl3G_gvfjE